
축약 연산자
프로그래밍을 하다보면 자기자신의 값에 변화를 주고 자기자신에게 다시 대입하는 경우가 정말 많은데
이를 위해서 발전된 문법이 바로 축약 연산자이다.
이와 같은 코드의 꼴을
A = A + 1
A += 1같은 형태로 더 간단하게 축약시켜 표현할 수 있는데
이때 +=과 같은 형태를 축약 연산자라고 한다.
예시)
+=
-=
*=
/=
!=
<<=
축약 연산자는 포인터 연산에서도 역시 사용할 수 있다.
int A = 10;
int* Ptr =&A;
(Ptr = Ptr+1) = (Ptr += 1);문자열
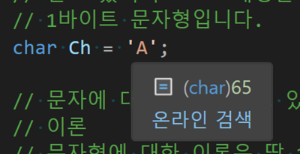
char 문자 자료형, 1byte
1byte값을 가지는 정수인 값으로도 볼 수 있다.(-127~127)
프로그래밍에서 문자는 매칭방식으로 표현된다
char 타입이고 값이 65인 경우 A라는 문자를 표시하도록 되어있다.
인코딩이라는 것은 문자 1개를 몇 바이트로 표현할지에 대한 것을 말한다.
처음에는 알파벳 말고는 다른 문자를 표현할 필요가 없었다.
이때는 1바이트만 가지고 필요한 모든 문자에 대한 표현이 가능했는데 이 때의
문자 매칭 인코딩 방식을 ASCII(아스키)라고한다.
인코딩이라는 것은 사용자가 입력한 문자나 기호들을 컴퓨터가 이용할 수 있는 신호로 만드는 것을 말한다.
초기에는 이를 표현하기 위해 1바이트로 충분했지만 프로그래밍이 전세계로 퍼져나가는 과정에서
다른 국가들의 언어를 문자로 처리해야 할 필요가 생기게 되었다.
한글이 1byte로 표현될 수 없는 이유
기본 아스키(0-127) 범위 내에서 한글로 나올 수 있는 문자 전체(11,172개)를 표현하기에는 너무 적다.
마찬가지로 전세계의 모든 글자를 표현하기에는 1byte는 너무나 작았다.
Extended ASCII(확장 아스키)
유럽의 글자들을 표시하기에는 부족했던 기본 아스키 코드의 범위를 확장하여 8비트로 표현하는 방식.
여전히 전세계의 언어를 표시하기에는 부족
국가별 인코딩
각 나라와 언어권에서 만든 독자적인 인코딩 시스템.
Shift-JIS(일본), GB2312(중국), EUC-KR(한국)등이 개발됨.
상호 호환이 되지 않고 역시나 특정언어 말고 다른 언어는 표현할 수 없다는 단점.
Unicode(유니코드)
전세계의 문자를 하나의 통일된 코드로 표현하기 위해 개발된 인코딩.
초기에는 2바이트(65536개)로 설계되었으나 부족했기 때문에 이후 확장됨.
ASCII와의 호환성을 유지하면서도 대부분의 언어를 표현 가능.
UTF-8 - ASCII는 1바이트 그외는 2~4바이트료 표현, 가장 널리 쓰이고 있는 인코딩 방식
UTF-16 - 고정적으로 2바이트로 표현하고 복잡한 문자에 대해서 4바이트로 표현하는 방식
UTF-32 - 모든 문자를 4바이트로 표현하는 방식
등의 포맷이 있음
문자열이란?
(string은 강의에서는 아직 다루지 않음.)
위에서 설명한 문자(char)들의 집합을 말합니다.
이 문자들의 집합을 표현하는 방식은 두가지가 있다.
멀티바이트와 와이드바이트
와이드 바이트
모든 문자를 고정 길이의 바이트로 표현하자.
일반적으로 와이드 바이트 문자열은
wchar_t str[] = L"Hello World";처럼 문자열 앞에 L을 붙인다.
멀티 바이트
문자의 종류에 따라 가변적인 길이로 문자를 표현하자.
다음과 같이 표현된다.
char str[] = "Hello World";
문자열은 따로 크기를 정하지 않으면 일반적으로 문자열 길이 + 1만큼의 크기를 가진다.
문자열의 마지막에 끝을 알리는 '\0'문자가 들어가기 때문에


배열
특정 자료형을 그 자료형의 크기*n개 만큼의 메모리 영역을 생성하는 것
배열의 이름을 그 배열의 첫번째 주소로 사용할 수 있고
아래와 같이 포인터처럼 연산도 가능해서 둘이 같은 거 아님?이라고 생각할 수 있지만 사실 다르다.
char str[6] = "Hello";
char a = *(str + 1);
cout << a;
// e 출력
같은 주소를 가리키고 있고 포인터 연산처럼 값도 역참조해서 가져올 수 있지만
일단 두 변수의 크기가 다르다.
배열은 생성될 때부터 크기가 정해져 있고 주소를 변경할 수 없지만
포인터는 그냥 주소를 가리키는 것이기 때문에 가리키고 있는 변수의 크기와 상관없이 주소값만 저장한다.

또한 포인터는 대상을 언제든지 바꿀 수 있지만 배열은 할당된 주소를 수정하는 것이 불가능
포인터는 해당 배열의 시작지점의 주소를 저장하고 있는 포인터 변수이고 언제든 다른 메모리주소를 가리킬 수 있다.
배열은 자신의 데이터를 저장할 공간의 크기가 정해져 있고 항상 메모리의 시작주소를 가리키고 있어야 한다.
따라서 배열은 증감연산자도 사용할 수 없다.

반복문과 조건문
반복문
while, do while, for문(range-based) 등이 있다.
for, while은 반복 시작전에 조건을 확인
do while 은 반복후에 조건을 확인
while(조건)을 쓰는 방식으로 작성
조건이 true(참)인 경우에는 while문 안의 코드를 반복해서 실행한다.
조건에는 ,를 구분자로 사용해서 여러가지 코드를 적용할 수 있지만 조건에 대해서는 가장 오른쪽의 메모리 영역으로 판단한다.
while(i++, i <= 10);이와 같은 코드의 경우 i++도 실행되지만 i <= 10이 while문의 반복 여부를 결정하는 조건이 된다.
증감연산자와 같은 코드들도 while문 안에 넣을 수 있기 때문에
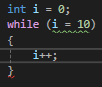
i == 10을 조건으로 쓰려다가 간혹 이렇게 i = 10같은 걸 조건으로 넣게되면 오류도 안생기고 무한루프에 갖히게 된다.
비주얼 스튜디오에서 표시해주지만 상수항을 좌측에 넣으면 오류가 뜨기 때문에 습관을 들이는게 좋다고 한다.

for(초기화; 조건; 증감)
while문을 더 쓰기 편하게 만든 구조이다.
break - 현재 반복문 내에서 빠져나온다.
continue - 이 문장 아래에 실행되어야할 코드들을 무시하고 다시 반복문의 처음(조건 검사, 증감 등)부터 실행
조건문
조건을 체크해서 해당 조건이 참이라면 조건문 스코프 내의 코드를 한번만 실행한다.
if문
if(조건)
{
실행코드
}
else
{
실행 코드
}
if의 조건에 해당하지 않는 경우에 코드를 실행한다.
else if(조건)
{
실행 코드
}
if의 조건에 해당하지 않으면서 다른 조건을 만족하는 경우에 코드를 실행한다.
switch-case문
switch(변수)
{
case 조건1:
코드 실행
break;
default:
break;
}조건에는 변수를 넣을 수 없다.
break를 넣지 않으면 다른 조건일 때의 코드까지 같이 실행된다.
대충 끗.
'개인 공부 및 프로젝트 > 국비과정' 카테고리의 다른 글
| 20240924 - MyPrintf, 객체지향 패러다임 (0) | 2024.09.30 |
|---|---|
| 20240923 - const, 랜덤 (0) | 2024.09.24 |
| 20240912 포인터와 참조 (4) | 2024.09.13 |
| 20240911 메모리와 연산자 (0) | 2024.09.13 |
| 20240910 프로그램 (0) | 2024.09.13 |